Existing 3D scene understanding methods are heavily focused on 3D semantic and instance segmentation. However, identifying objects and their parts only constitutes an intermediate step towards a more fine-grained goal, which is effectively interacting with the functional interactive elements (e.g., handles, knobs, buttons) in the scene to accomplish diverse tasks. To this end, we introduce SceneFun3D, a large-scale dataset with more than 14.8k highly accurate interaction annotations for 710 high-resolution real-world 3D indoor scenes. We accompany the annotations with motion parameter information, describing how to interact with these elements, and a diverse set of natural language descriptions of tasks that involve manipulating them in the scene context. To showcase the value of our dataset, we introduce three novel tasks, namely functionality segmentation, task-driven affordance grounding and 3D motion estimation, and adapt existing state-of-the-art methods to tackle them. Our experiments show that solving these tasks in real 3D scenes remains challenging despite recent progress in closed-set and open-set 3D scene understanding.
Existing 3D scene understanding methods are heavily focused on understanding the scene on a coarse object level by detecting or segmenting the 3D object instances. However, identifying 3D objects is only an intermediate step towards a more fine-grained goal. In real-world applications, agents need to interact with the functional interactive elements (e.g., handles, knobs, buttons) and reason about their purpose in the scene context to successfully complete tasks.
We introduce SceneFun3D, the first large-scale dataset with geometrically fine-grained interaction annotations in 3D real-world indoor environments. We aim to encourage research on the following questions:
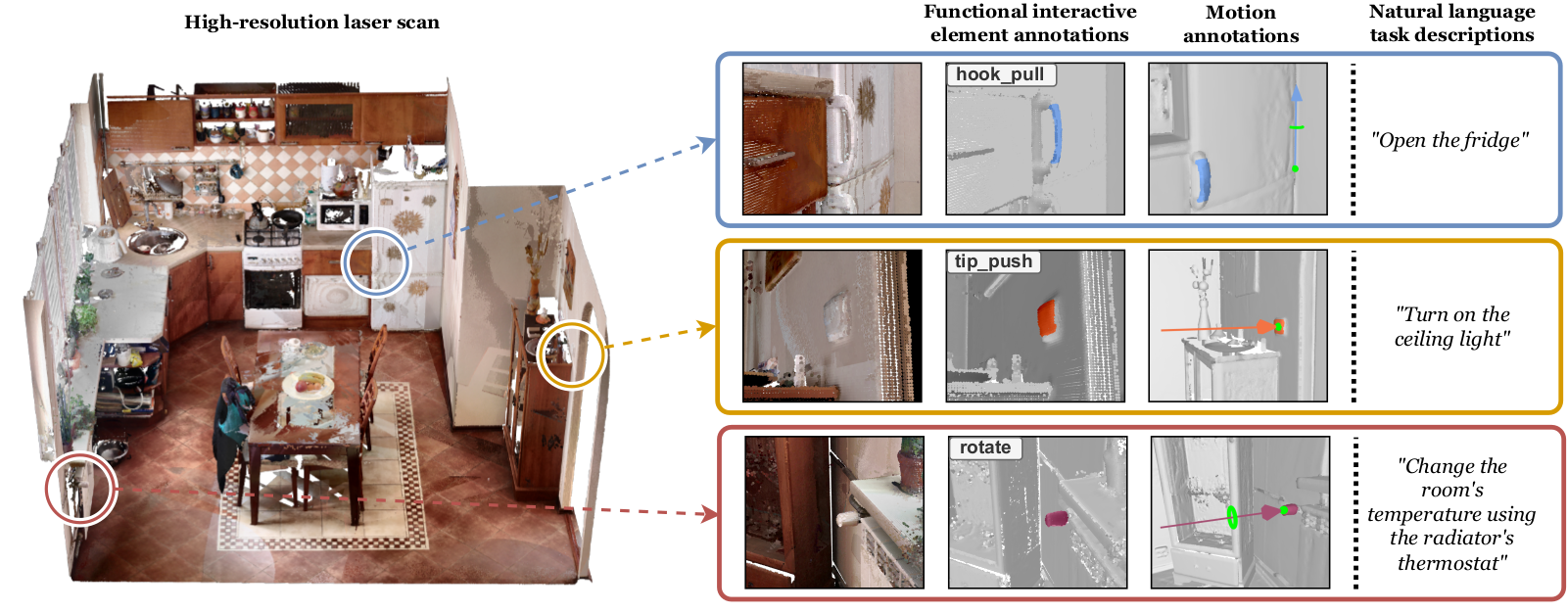
SceneFun3D contains more than 14.8k annotations of functional interactive elements in 710 high-fidelity reconstructions of indoor environments. These annotations comprise a 3D instance mask followed by an affordance label. We define nine affordance categories to describe interactions afforded by common scene functionalities.
Beyond localizing the functionalities, it is crucial to understand the purpose that they serve in the scene context. To this end, we collect free-form diverse language descriptions of tasks that involve interacting with the scene functionalities.
To achieve holistic scene understanding, we collect annotations of the motions required to manipulate the interactive elements.
We introduce three novel 3D scene understanding tasks, namely functionality segmentation, task-driven affordance grounding and 3D motion estimation. Additionally, we propose closed- and open-vocabulary methods to tackle them and perform systematic benchmarking.
Given a 3D point cloud of a scene, the goal is to segment the functional interactive element instances and predict the associated affordance labels.
Given a language task description (e.g., “open the fridge”), the goal is to predict the instance mask of the functional element that we need to interact with and the label of the action it affords.
In addition to segmenting the functionalities, the goal is to infer the motion parameters which describe how an agent can interact with the predicted functionalities.

Our aim is to catalyze research on robotic systems, embodied AI and AR/VR applications. In robotics (left), localizing visual affordances and grounding them to natural language task descriptions is a crucial skill for embodied intelligent agents. By providing accurate 3D affordance masks, we facilitate the generation of realistic human-scene interactions (right), unleashing new directions in virtual human applications.
@inproceedings{delitzas2024scenefun3d,
title = {{SceneFun3D: Fine-Grained Functionality and Affordance Understanding in 3D Scenes}},
author = {Delitzas, Alexandros and Takmaz, Ayca and Tombari, Federico and Sumner, Robert and Pollefeys, Marc and Engelmann, Francis},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}